In this post we’ll look at the different formats that tend to be used around the topic of website archiving. This post is in no way an exhaustive list but it should get you up to speed with the most common formats such as WARC and CDX.
WARC/ARC Format
The WARC format is a revision of the Internet Archive’s ARC File Format. Both versions of the format are for storing the content obtained during web crawling. This consists of the content in the requests made to web servers as well as the responses from those servers.
The latest version of the format is v1.1 and can be found on the IIPCs Github . The specification gives all the information needed to deal with WARCs and should be kept close to hand.
WARCs and ARCs are typically found with the extension .warc and .arc respectively. However to save space they also have a gz compressed versions with extensions .warc.gz and arc.gz respectively. It’s important to realise that the records in the (W)ARCs are compressed separately instead of the entire file so compressing or uncompressing using a standard compression tool will not work and can result in WARCs that are incompatible with playback software.
A list of tools that understand the WARC format can be found at archiveteam.org. I developed a tool for viewing the raw content of WARC files such as records and headers. This tool is called WarcRawContentExplorer and can be seen in the image below.
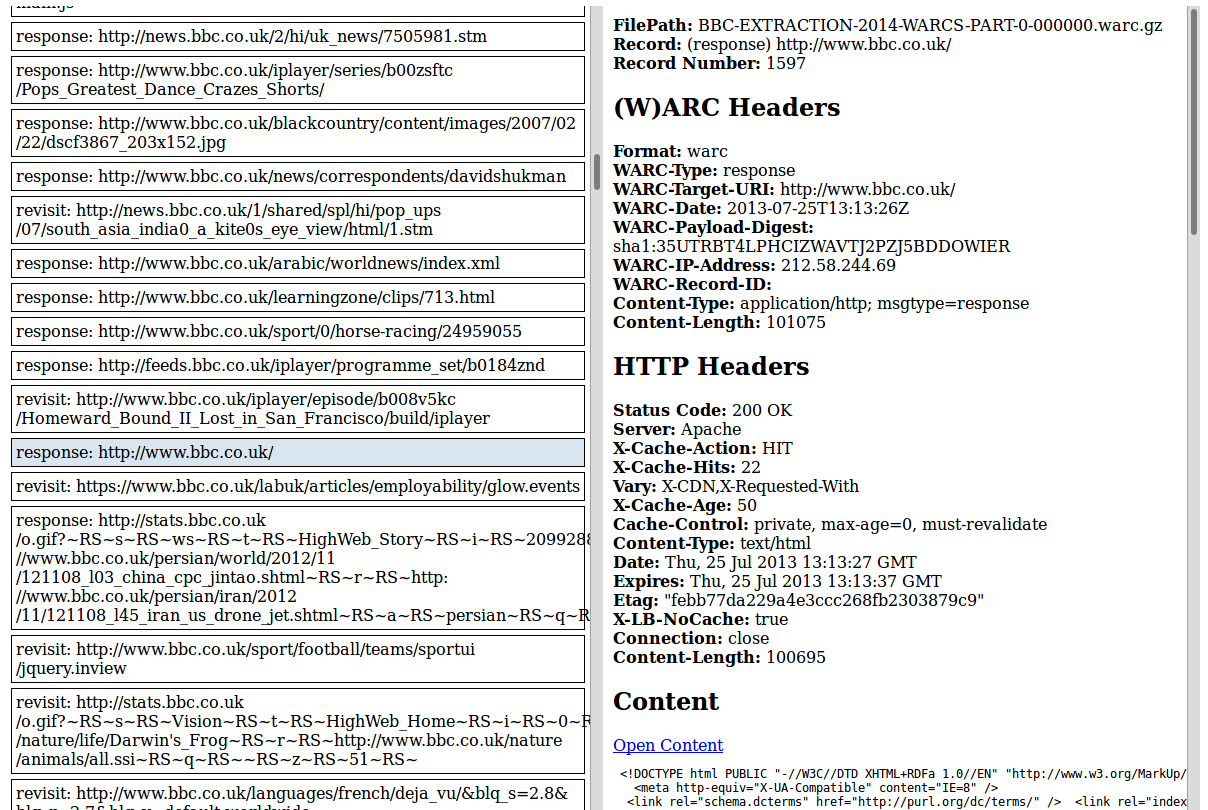
Viewing Content in WARCs
To view the raw content of WARCs the WarcRawContentExplorer tool can be used. You can find the tool on github. The WarcRawContentExplorer script starts up a server on localhost:8000 which allows you to upload WARC files or browse WARC files in the same folder as the script. The interface doesn’t try to reconstruct the websites inside the WARCs. It’s use is for exploring the exact records of the WARC file, the metadata attached to them and their raw content.
CDX Index Format
A CDX file is a web archiving specific indexing format. It is used to produce an index over the WARC files in a collection. There are several different indexing methods on WARCs that can be used but they all build on top of CDX files and often require CDX files to be generated first.
An example snippet of a CDX file is shown below:
CDX N b a m s k r M S V g
uk,co,bbc)/ 20100531101456 http://www.bbc.co.uk/ text/html 200 KRKCVCVHMDGMCADAICP…
uk,co,bbc)/ 20111024195325 http://bbc.co.uk/ warc/revisit – 6G7QDRZIIE4GD3JIDKA3CU…
As can be seen the first line is a header describing what the fields are and then each row underneath that represents a single record in the WARC. Each field in a row is separated by a space. Each letter in the header after CDX represents what the nth field in each row is. A complete list of what each letter is can be found in the OpenWayback source code.
WACZ Format
A relatively new archiving format compared to others on this page. The WACZ format proposal is available on github and is backed by the well respected WebRecorder project. In summary, the WACZ format is an encapsulation of WARC and CDX files along with extra metadata to make a more portable web archive format.
Other Formats
Some other lesser used formats I have come across are listed below.
Dublin Core Metadata Element Set
Used by the Archive-it tool. More details about the format can be found at dublincore.org.
HAR
A HAR file is encoded with a simple JSON format, which is both easily created and consumed. Each HAR file contains a list of loaded pages, and a list of entries for each requested resource for each page. The main difference between a HAR and WARC is that HARs contain lots of timing information and are used for writing the results of page load times to file. As a result, HAR files tend to be used for timing websites and browsers. Tools exist that can convert a HAR file to a WARC. However I don’t know what information is lost in the conversion or capture by using a HAR so I would not recommend using HARs for storing web archive content.